The demands on any application vary over time. Whether its the daily changes in
traffic volume on an online shopping platform or massive load from
processing large sets of data, applications and their underlying infrastructure
must be able to cope with changes in demand. It is important to both avoid
downtime when demand increases as well as to avoid high costs of running many
machines when demand decreases.
It is not always easy or possible to predict what kind of resources will be
necessary when creating a Kubernetes cluster. The decision one must make is
whether to choose fewer nodes and risk downtime when the website is busy or
choose more nodes and risk paying for unused resources.
To assist with these scenarios, Catalyst Cloud Kubernetes Service provides a
feature called cluster auto-scaling. Cluster auto-scaling enables a
Kubernetes cluster to automatically increase or decrease the number of working
nodes in response to changes in resource demand. In this section we will explore
how you can use auto-scaling in your Kubernetes cluster.
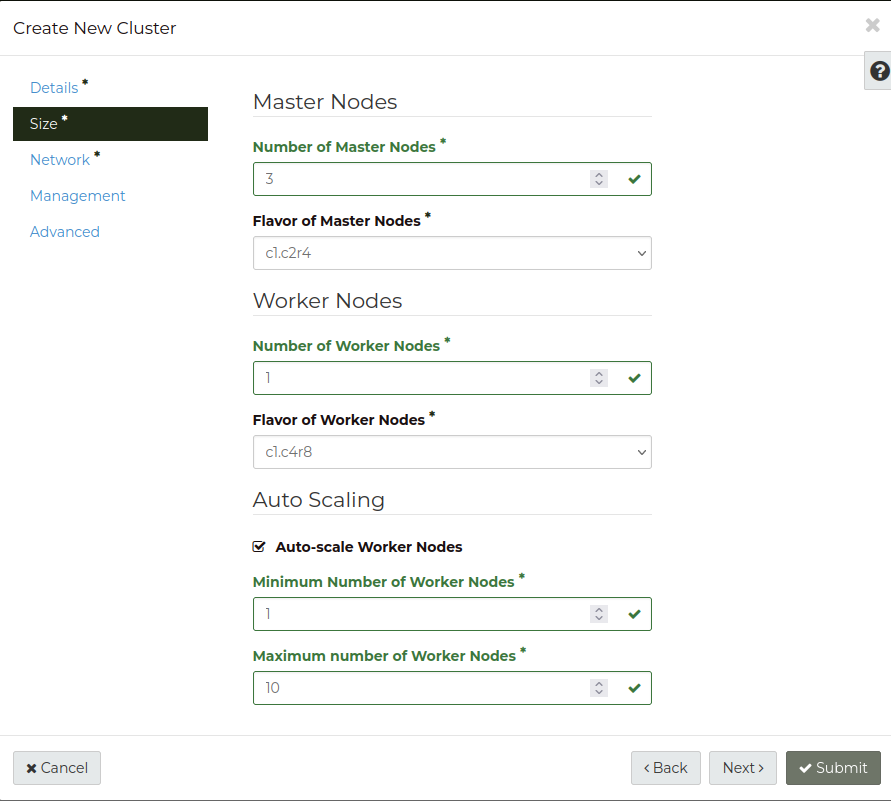
Create cluster with auto-scaling in the web dashboard.
Note
Auto-scaling does not use the current CPU and memory usage as metrics to
resize the cluster, but rather the CPU and memory reservation
(resource requests) in the pod specification to determine if the
capacity allocated to a worker node.
The value for min_node_countmust be greater than zero. The value for
max_node_count must be greater than the value for min_node_count. The
value for min_node_count overrides the –node-count argument if it is
lower.
Note
When auto-scaling is enabled, the value displayed for node count in the
dashboard and command line will not reflect the actual number of worker nodes
if the auto-scaler has made changes.
This is a bug and we are working to address this soon.
The auto-scaling feature requires the use of resource requests for CPU and
memory in the pod specification. The following pod specification
illustrates the use of resource requests:
The conditions that trigger a cluster resize are explained below:
Scale out: a worker node is added to the cluster when the Kubernetes
scheduler is unable to allocate a pod to any existing worker node due to
insufficient capacity.
Scale in: a worker node is removed from the cluster when the cluster
resource usage drops below the defined threshold (by default 50%) for a
period of time.
As you might expect, auto-scaling also works in the other direction too.
Specifically it should scale the number of nodes back down again when they are
no longer needed.
Continuing with the previous example, let’s scale the number of Pods back down
to one and see what happens.
Auto-scaling is a versatile feature for managing demand on cluster resources.
It enables your Kubernetes cluster to scale up or down when needed in
response to changes in workload. It ensures that your application can
cope with increased load and more importantly that you only use the resources
you need.